Yesterday the PHPVerse online-conference was taking place. For reasons unrelated to what I am writing about here I didn’t participate. And let me be 100% clear: This is a personal opinion that is based on observations around the conference, not on the content itself!
What is PHPVerse?
PHPVerse is an online conference organized by Jetbrains and free to attend for everyone registered.
The idea is to connect different parts of the splitted PHP-Community which I endorse! So for this edition there were people from the Symfony-, WordPress-, Laravel- and the Drupal-Community doing sessions along with people vocal on the internals mailinglist, maintaining the PHP package manager and from the PHP Foundation.
But this is not about the content that these people brought. What hit me were three fundamental things about “The Community” that in my opinion need to be addressed differently and why I am increasingly weary of such events.
1. The Community
What community are we talking about here. Or let me ask this question slightly different: Which parts of “The Community” are we **not** reaching?
I realised that when I wanted to toot about the event: It doesn’t have an account on mastodon…
🤯
Yes! I know! There are several other social networks out there.
And on the main website of the event there are several social networks showing up right at the top: X, Facebook, LinkedIn and BlueSky.
Given that there is such a thing as a PHP-Community Mastodon server (at https://phpc.social) where an integral part of the PHP-Community is “hanging out” it seems like an odd choice to not at least include that in that list.
I understand that a “Free” event still needs to pay off for someone and that it is far easier to track “interactions” on walled-garden “social” networks. But if you want to do something **for** the community without a vital part **off** the community, that seems like “Doing it wrong™”
2. The time
Interesting was also the timing. When doing an online event, it is really hard to please everyone. Especially when you want to do an event in “only” 8 hours. Due to the nature of the world the PHP-Community is online almost 24h a day. It is spanning from New-Zealand, Australia and Japan on the east side all the way over to the Americas with Alaska and Hawaii reaching out furthest west. (Yes! There are some people even nearer to the date-line, I know!).
The event was set to happen from 11:00 UTC to 16:30 UTC. Which means 23:00 through 4:30 in Auckland. That requires some commitment to follow this event from there. Even as far west as the Indian Subcontinent – where the event took place from 16:30 through 22:00 that requires some commitment to follow that late into the evening.
When I realized that I immediately had to think about this tweet from 2021:
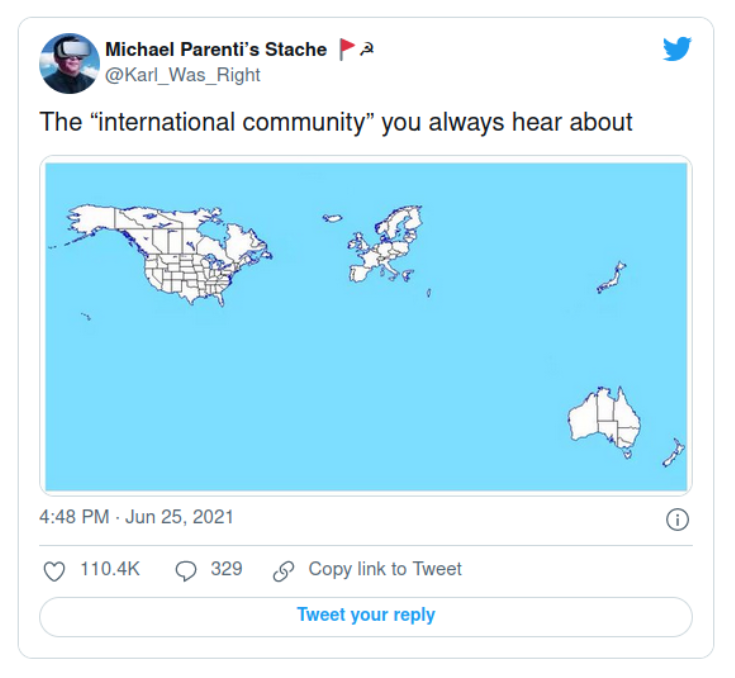
Only that this time event Japan, Australia and New Zealand are missing.
Again: “The Community” is actually only a part of the community that we are talking about.
3. The people
And then I stumbled upon a toot from Pauline Vos:
Just saw the trailer for the PHP documentary shown at PHPVerse…
ZERO women? Are you serious? 5 women (including at least 3 past or present core developers that I know of, and the executive director) on the @thephpf , and the story of PHP includes ZERO women?
Not to mention those prominent in the community that aren’t part of the Foundation itself. You can’t be serious.
Yes! There are not that many women around in the PHP Community. One might think. But actually there are. But with this kind of marketing, that amount will – to put it mildly – not increase.
Again: A huge part of the community not only lost but actually alienated.
Takeaway
To summarize: Time, Interaction and trailer-Content indicate that “The Community” the PHPVerse is talking about, is the European and North-American male dominated part that is still hanging out on the BigCorporation networks.
That is not the PHP Community I know and that I consider myself a part of. On the contrary! That seems to be the image that the PHP Community needs to get away of to actually become a world-wide, welcoming, vibrant, and healthy community.
Oh! And before you start responding with reasons why something doesn’t work or can’t be done differently: Think about this:
Where there’s a will, there’s a way; where there isn’t, there’s an excuse.